
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- json
- Stanford
- slideshare
- computer_setting
- Statistics
- linux
- tab
- git
- seq2seq
- nlp
- natural_language_processing
- review
- text
- machinelearning
- error
- code
- pip
- terminal
- computer
- paper_review
- language_model
- Ai
- github
- deeplearning
- gensim
- Standford
- cs231n
- cs224n
- install
- Vim
- Today
- Total
NLP/AI/Statistics
순환신경망: RNN(Recurrent Neural Network) 본문
텍스트는 연속된 토큰의 형태로 시퀀스 데이터에 속한다.
이러한 비정형 데이터를 처리하기 위해 가장 유용한 딥러닝 모델을 순환신경망이라고 한다.
순환신경망 모델은 이미지처리에서 주로 사용되는 CNN(Convolutional Neural Network) 모델과 달리
데이터의 연속적인 정보를 저장하여 순차정보를 학습하는 특징이 있으며
입력 시퀀스의 길이를 고정할 필요가 없기 때문에 텍스트를 처리하기에 용이하다는 특징이 있다.
순환신경망의 대표적인 모델로는 Vanilla-RNN (Recurrent Neural Network), LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit)이 있다.
Vanilla-RNN이 흔히 RNN이라고 칭하는 모델을 의미하며, LSTM과 GRU는 이 모델의 변형 모델이라고 생각하면 된다.
Vanilla-RNN은 보편적으로 RNN이라고 언급되기 때문에 이 글에서도 RNN이라고 칭할 예정이다.
LSTM과 GRU는 이후의 글에서 설명할 예정이다.
기본적으로 RNN은 아래의 그림처럼 구성된다.

(주황색: 입력층, 초록색: 출력층, 회색: 은닉층)
입력 벡터 $(x_1, x_2, ..., x_t)$에 대하여 출력 벡터 $(y_1, y_2, ..., y_t)$를 출력하는데,
이 때 입력 벡터와 출력 벡터 사이의 메모리 셀을 통하면서 이전 시퀀스의 정보를 기억하게 된다.
메모리 셀(은닉층)은 두 가지 역할을 한다. (현재 시점: $t$)
첫 번째로 시점 $t$의 출력을 위해 출력층으로 전달
두 번째로 시점 $t$의 학습 정보를 다음 시점 $t+1$로 전달
이처럼 RNN 모델은 이전 시점의 학습 벡터를 다음 시점으로 전달하는 재귀적인 특성을 나타내며
이러한 과정을 통해 이전 순차 정보를 압축하여 시퀀스 정보를 저장하게 된다.
앞서 말했던 바와 같이 RNN과 같은 순환신경망 모델은 기본적인 신경망 모델인 FFNN(FeedForward Neural Network)과 같이 입력 벡터의 길이를 동일하게 맞추지 않아도 된다.
순환신경망 모델은 입력 방식에 따라 수행되는 task, 설계가 다르게 나타나는데 크게 세 가지 형태가 있다.
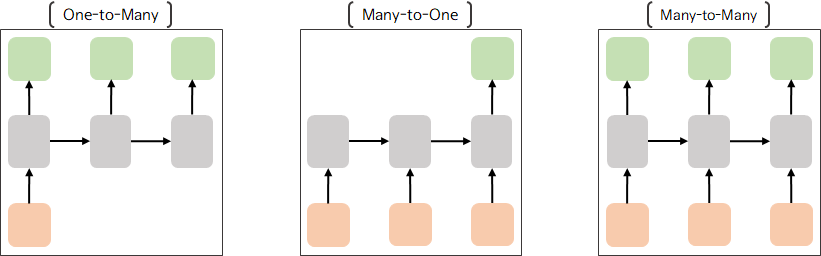
One-to-Many (일대다) 방식은 OCR, Image Captioning 과 같이 이미지를 입력으로 연속된 시퀀스를 출력하는 task에서 활용된다.
Many-to-One (다대일) 방식은 스팸 메일 분류, 감정 분류 등의 분류 모델에서 사용되는 방식으로,
연속된 시퀀스를 입력으로 스팸인지 아닌지 혹은 긍정인지 부정인지의 분류 값을 출력하는 task에서 활용된다.
Many-to-Many (다대다) 방식은 영어 문장을 입력으로 한국어 문장을 출력하는 기계번역이나
질문을 입력으로 답변을 출력하는 챗봇 시스템과 같이 입력과 출력 모두 시퀀스 형태인 task에서 활용된다.
이제 RNN의 내부적인 수식에 대하여 보면,
하나의 시점 $t$의 벡터 값들을 다음과 같이 정의한다.

위의 그림은 $t-1$ 시점과 $t$ 시점 사이에서의 벡터 전달을 수식적으로 표현한 그림이다.
이 때, 빨간색으로 표기한 $h_{t-1}$과 $h_{t}$는 각 시점에서 은닉층으로부터 나온 은닉 벡터를 의미하며
파란색으로 표기한 $w_{x}$(입력 가중치), $w_{h}$(은닉 가중치), $w_{y}$(출력 가중치)는 신경망의 각 층에 대한 가중치(weight)값을 의미한다.
신경망에서 bias 값이 포함되어 계산되지만, 그림에서는 간략한 설명을 위해 생략한다.
각 표기와 함께 위의 그림을 살펴보면,
우선 시점 $t$에서 입력층은 입력 벡터 $x_t$와 입력 가중치 $w_t$의 연산으로 은닉층에 입력된다.
#. 신경망 기본 연산 $f(x) = wx+b$ w: weight, b: bias
은닉층은 입력층으로부터 온 $w_{t}x_{t}$를 전달받으며,
추가로 이전 시점 $t-1$의 은닉 벡터 $h_{t-1}$와 은닉 가중치 $w_{h}$의 연산 값을 함께 전달받는다.
즉, 은닉층은 새로운 $t$시점의 은닉 벡터 $h_{t} = tanh(w_{t}x_{t} + w_{h}h_{t-1} + b)$를 얻게 된다.
#. 은닉 벡터를 위한 활성화 함수로 $tanh$를 주로 사용하지만 $ReLU$를 사용하기도 한다.
이렇게 생성된 $h_{t}$는 또다시 다음 시점 $t+1$로 전달되어 순환하게 된다.
또한, 출력층은 은닉층에서 계산된 $h_{t}$와 출력 가중치 $w_{y}$의 연산 값을 비선형 활성화함수를 통해 벡터의 변환을 거쳐 $y_{t} = softmax(w_{y}h_{t}+b)$를 출력한다.
#. 비선형함수로는 softmax 이외에 ReLU, sigmoid 등이 활용된다.
이처럼 RNN은 이전 시점의 학습 결과의 영향력을 받는다.
하지만 이러한 RNN은 길이가 짧은 시퀀스에서는 좋은 성능을 보였으나 길이가 길어질수록 성능이 감소되는 경향을 보였다.
어떤 언어에 대하여 문장이 길어지면 길어질수록 앞의 단어가 기억이 안날 때가 있다.
특히, 한국어에서 문장이 길어질수록 주어와 서술어의 거리가 멀어지고 점차 주어가 뭐였는지, 잊어버리는 경우가 발생한다.
즉, RNN에서 $t$ 시점까지의 거리가 길수록 $x_1$의 정보는 $x_t$까지 전달되는 과정에서 정보손실이 발생하게 된다.
이러한 정보손실 문제를 장기 의존성 문제 (Long-Term Dependency problem) 이라고 하며
이 문제를 해결하기 위한 모델로 LSTM 모델이 소개되었다.
LSTM 에 대한 설명은 다음 글에서 설명할 예정이다.
'NLP' 카테고리의 다른 글
| Sequence to Sequence (0) | 2020.12.08 |
|---|---|
| 순환신경망: LSTM(Long Short Term Memory) (0) | 2020.11.25 |
| 문서 유사도: 코사인 유사도, 자카드 유사도, 유클리드 거리 (0) | 2020.10.19 |
| Word Representation: TF-IDF (0) | 2020.10.15 |
| Word Representation: Bag-of-Words (0) | 2020.10.12 |

